Priority is a classic example of a proxy variable that leads to distortion of service management practices. What do I mean by “proxy variable”, why do I say that this hallowed service management concept leads to distortion and what might we do to remedy this issue?
Priority as a Proxy Variable
The term “proxy variable” was defined by Don Reinertsen. It is a metric used in a management system that stands in (thus, is a “proxy”) for some other, more fundamental, metric. Proxy variables often end up having a life of their own and are managed for their own sake, forgetting the underpinning principle for which they stand.
In the case of IT service management, priority is commonly treated as an attribute of many entities that are managed by a service management discipline. Thus, changes, incidents, problems and so forth all have priorities. Priority is typically an ordered value defined within a specific range that allows users to sort and to filter the objects based on priority. Thus, priority often is given a range of values such as “1-2-3” or “critical-normal-low”.
Priority has two common uses. First, it is used to identify the order in which an activity should be performed, relative to other activities. Second, it is sometimes associated with a level of service—most often the response time and the resolution time—for the performed activity.
For what is “priority” a proxy? The recommendation of ITIL® is to calculate priority based on impact and on urgency. So, according to ITIL, what we really want to manage is the impact and the urgency of an event or of a requirement. Some of those events, such as many changes, serve to increase value to the service provider or to its customers. Other events, typically incidents, serve to decrease that value. So all activities performed around those events contribute to a net change in value. In fact, impact and urgency are themselves proxy variables for net change in value. So priority is a proxy for other proxies.
Why use a proxy variable instead of managing directly the impact and urgency or, for that matter, the net change in value? There are several reasons for this:
- It can be very hard to accurately assess the net change in value, especially before the action is performed
- Indeed, we can only really talk about the probability of a net change in value, and that probability, too, is often hard to assess
- Some actions have little direct impact on value, but are prerequisite to other actions that do affect value change
- We may need a means to compare and to order all sorts of actions, such as working on incidents, problems, changes, events, projects, operational tasks, etc.
Priority distorts
If you are already convinced that the use of “priority”, as recommended by “best practice”, is problematic, you may wish to skip directly to the discussion of an alternate approach.
Why do I say that managing according to priority leads to distortion? There are many reasons for this, some depending on how an organization implements prioritization, others being more systematic in nature. Let’s look at the examples.
Urgency is misunderstood
In virtually every organization I have seen, the concept of urgency has been misunderstood. (I have discussed impact and urgency at length here.) Although these organizations create matrices of impact vs. “urgency” to calculate priority, an analysis of the so-called “urgency levels” typically defined reveals them to be nothing more than an alternate scale of impacts. The matrices are really comparing one scale of impact to another scale of impact. As I have discussed this issue in detail elsewhere, I will not repeat it here. The important point is that urgency is simply ignored by many organizations.
Impact is measured by yet other proxy variables
Since it can be so hard to assess impact, especially before the work of management is completed, many organizations use yet other proxy variables to assess impact. The most common one is the number of users impacted. Recognizing that such a proxy variable can only be very approximate (which has the greater impact: one person prevented from signing a multi-million dollar sales contract or 100 people who cannot file their weekly time sheets?), some organizations make a further mess of things by factoring in such elements as whether the impacted person is a “VIP” or not. If the production equipment of a factory risks failing if it is not lubricated in time, which person has the greater impact? The relatively unskilled person who does the lubrication or the senior vice president for engineering who specified the purchase of the equipment requiring manual lubrication?
Insufficient granularity of proxy variables
Suppose, for the sake of an example, that the impact of any action can range from losing 100 million to earning 100 million (a small to medium-sized organization). Are three or four categories of impact (Large, Medium, Small) sufficient to distinguish among everything that could occur within that range? If we agree that there is a really big difference between gaining 5 million and gaining 50 million, can we adequately model that difference using the typical impact scales in place? I think not. The result is that the vast majority of items are handled on other bases, such as the first-in, first-out principle. This is precisely what happens when a team is faced with a queue of 10 items, all of which have a priority of “normal”.
Failure to assess downside risk
Most assessments of impact blithely ignore the downside risk of the impact, focusing only on the optimistic value of the activity. Suppose a team has two actions to perform. One action will cost at least 1’000, is supposed to return 10’000 in value, but has a 40% risk of failure. The other action will cost no more than 500, is supposed to return 5’000, but has 10% risk of failure. Which action has the greater impact?
I venture to guess that most organizations have absolutely no idea how to assess and compare the probable impacts of the two actions (which involves using Bayes Theorem). Furthermore, most organizations would compare only the upside potential, without considering the risk at all. Thus, in the example above, a theoretical benefit of 9’000 (10’000 – 1’000) is compared to a theoretical benefit of 4’500 (5’000 – 500). The same psychology is behind our buying lottery tickets, where the probability of ever gaining anything is hardly more than 0, as opposed to investing those modest sums in something of almost sure value. Do we really want to manage our organizations on a wing and prayer? I am not against prayer, but don’t forget the saying about all others paying cash.
Basing impact on the component rather than the action
Faced with the need to assess impact (and thus priority) very quickly and the difficulties in doing so, many organizations use yet another proxy variable. They look at the component or the system concerned, one to which they have previously assigned a value for how critical that component is. For example, a server used to operate the manufacturing process of a company is called “critical”. Another server used to operate accounts payable is considered to be less critical. When an incident or a change concerns the first server, its impact is automatically determined to be the highest available.
And yet, it should be clear that not all incidents, changes and operational tasks for the same component have the same risk, the same impact, the same urgency.

Unequal application of the priority principle
The real question for any team or person that priority should answer is, “What should we do next?” In other words, out of all the different types of work items for which a team is responsible, what is the next item to perform? In reality, item priority is frequently applied in a haphazard way. The most common exception is to limit the use of priority to unplanned actions. Thus, priority might only concern events and incidents. This inequality is further enforced by policies that are commonly found in organizations. For example, it is a common policy that an assigned incident takes priority over all other activities.
But is this always what we really want to do? If we plan to introduce into production during the weekend a new system that should improve company productivity by 30% and if there is also an incident detected Friday night for another system that is only used Monday–Friday from 8:00–18:00, which has the higher priority?
Comparing apples and oranges
Even if we use the same scale of priorities for all activities, the methods used for calculating those priorities are often very different from one type of activity to another. Comparing a change to an incident, for example, the ways in which we assess impact and urgency are often different, or have special weighting factors introduced. We end up making arbitrary comparisons because the units of our scales of impact and urgency are different.
This is already and issue for any calculation based on impact and urgency. If priority is a purely scalar, unit-less metric, by what logic can we derive it from a combination of numbers of people or the criticality (typically used for impact) and hours or days (the unit that should be used for urgency, but is typically ignored)? The answer? Voodoo logic!
In summary, the priority system used in many organizations is often far removed from the real values that need to be managed, are applied in inconsistent ways, are fundamentally illogical and are largely arbitrary. They represent a certain overhead for calculation that probably does not make much of an improvement over any other common sense, seat of the pants assessment of order of handling. Perhaps it is Voltaire’s view of the distribution of common sense that has led us to seek the use of so many proxy variables.
So what can we use instead?
A metric commonly applies in organizations that organize work using Kanban is the Cost of Delay (CoD). This metric is intuitively comparable to the principles of urgency and impact, but works in a direct manner, rather than via proxy variables.
The background for the concept of CoD is the agile principle of delaying decisions until the last responsible moment. This principle contrasts with the idea of doing work as soon as possible, as opposed to as late as possible. Why delay? There are essentially two reasons. First, by delaying we learn more about the work to be done. Often, when work has been requested by a customer, that customer’s view of what needs to be done evolves over time. By delaying, we avoid doing work based on a requirement or an idea that changes before we have finished the work. This is a common issue, for example, in the development of software.
Second, by delaying our commitment to doing work, we leave ourselves open to work on other items that might arise later, but should be done sooner. By doing work as early as possible, we increase the probability of having to stop doing that work and start doing other work, in other words, switching the context of our work. When we have a large amount of work in progress, there is a tendency to frequent context switching, which turns out to increase significantly the overall time required to do that work and delays the completion of the work. So, delaying until the last responsible moment complements the Kanban concept of limiting the amount of work in progress and focusing on improving the flow of whatever work to which you are committed.
Therefore, the concept of CoD is a means of determining which work can be and at what cost. There are four main patterns for CoD, according to the framework espoused by David Anderson:
- Fixed Date
- Standard
- Intangible
- Expedite
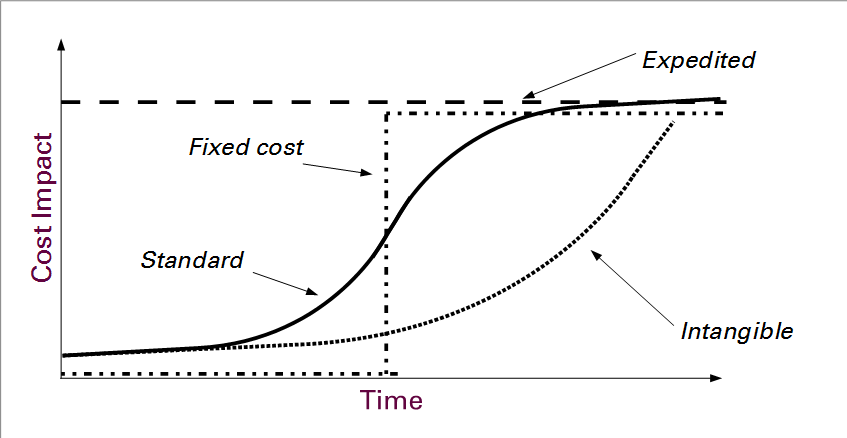
Fixed Date
In the Fixed Date profile, work needs to be delivered at a specific date and time. If it is delivered earlier, there are no benefits to the customer. If it is delivered later, the customer will suffer specific costs. Thus, the Fixed Date pattern clearly implements the concept of urgency.
Take as an example a failure in a system used to pay the employees of the company. Assume that a payroll run is made once per month. The failure must be remediated in time to execute the payroll. Resolving it sooner gives no specific benefits. Resolving it later incurs all sorts of costs to the unpaid employees.
Standard
Most work has a standard cost of delay. There is no particular urgency. However, the sooner the work is delivered the sooner is the value of the work realized. Most work falls into this pattern. Some describe the relationship of cost to delay as a straight line, with a direct proportion. Others consider that cost has more of an S-curve relation to delay. In other words, a short delay incurs little cost. More often than not, the customer, too, has to prepare for using the work output, so there is little cost in delaying. But, at some point, the cost increases sharply. This may correspond to opportunities that are seized, or not. Finally, the increase in cost due to additional delay levels out.
Intangible
This pattern, with its unfortunate name, refers typically to work done internally to an organization, without a direct output to an external customer. Think of the work maintaining the rail infrastructure for train service. If the trains are running well today, there will be no cost to delaying the maintenance by a day, a week or a month. But, sooner or later, there will start to be more and more issues. The ride becomes increasingly bumpy. Speeds might have to be reduced on certain stretches. And finally, derailments start to occur.
This is similar to the situation in IT. We might have a database infrastructure standardized on a certain version of the database management software. We know that we shall have to upgrade that software, but it is very complicated to do and we shall want to put it off. There will be no cost in delaying the work for short periods of time. But the day will come when an application needs to be upgraded and the new version only works with a new version of the database manager. Or the developers want to benefit from a new feature in the database manager. So, the cost of delay is very low at first, but it gradually increases until the cost accelerates at a high and utterly unacceptable rate.
Expedited
We have all faced situations where we are required to stop everything we are doing and devote ourselves to doing work immediately, to be delivered yesterday. This work might be triggered by an unexpected, external event. It’s as if we discovered the year 2000 bug on 31 December 1999. The cost of delay is immediate and high. We clearly need to focus our attentions on this work.
Expediting work because of the CoD pattern should be distinguished from expediting for other reasons. Managers manipulating the production schedule for personal reasons; salespeople making commitments to deliver that they should never have made—these are examples of catastrophic ways of managing the flow of work that should never occur. For this reasons, Kanban recommends the strictest of limits on expedited work. For expediting is a vicious cycle. Once you get hooked by the habit of expediting, nothing ever gets done unless it, too, is expedited.
I think the term “preemptive” would be better than “expedited”. “To expedite” just means “to go faster”. “To preempt”, however, also highlights the fact that you stop working on whatever you are already doing to complete the work item. But, given the existing tradition, I will not insist on changing the name.
So what’s the difference?
What, you might ask, is the difference between Cost of Delay and priority based on impact and urgency? Surely, Cost is the same as Impact and Delay is the same as Urgency? If you look only at the theory, admittedly the concepts are very close to each other. And happily so, for this means that service managers accustomed to priority based on impact and urgency can easily switch to using CoD. But why bother?
Everyone intuitively understands CoD. You do not have to explain it to your customers. Priority matrices are voodoo. The complicated definitions that underpin the impact and urgency levels, the somewhat arbitrary calculations of priority based on those definitions, the need to manage exceptions to those rules are very hard to explain to users of a service. And that includes the cases where the calculations have been agreed with the customers.
CoD is not a proxy variable. It is a direct economic indicator. It is precisely what you want to manage and to optimize. It’s not a stand-in for anything else that might distort the results.
CoD is infinitely scalable. It does not require you to make arbitrary cut-offs between three or four levels of impact or urgency.
CoD makes it easy to determine what work to do next when there is an input queue of multiple items. If an item is expedited, and if you are not currently working on an expedited item, everyone knows that it is the next thing to do. If an item has a fixed due date in 3 months and it will take 2 weeks of work to complete, everyone knows that an intangible or standard item that takes 1 day should be taken first. What about cases where the differences are not so clear-cut? Some organizations will factor in the notion of risk. All things being equal, the less risky item should be done first. And if, from a CoD perspective, all things really are equal, then it makes no difference which item is done first..
CoD helps you to focus on finishing work. This contrasts with a push-based system with no limits to work in progress that focuses on starting work. This is especially true when, as described above, urgency is misunderstood and interpreted as another form of impact.
CoD also contrasts with the use of agreed service levels to decide when work must be completed. When an organization links service levels to priority, it artificially constrains delivery dates to a fixed set up typically three to five values. Instead of forcing the provisioning team to think about when its customer really needs the work, once again it uses a proxy variable—resolve time—that is, at best, an inflexible average value. For example, if we agree that priority 1 work should be resolved in one hour, priority two in four hours, priority three in 24 hours and priority four in one week, is it really true that all priority one work needs to be completed in one hour, at worst? Aren’t there cases were two hours, or three hours, or even more, would be largely sufficient?
Note, too, that different service levels need to be agreed for each different type of work. The deadlines that we might fix for handling incidents are hardly applicable to handling changes or other types of work. This makes for a much more complicated set of proxy variables that need to be juggled to determine when work is due. What is the urgency? What is the impact? What is the priority? What is the type of work item? What is the applicable SLA? And finally, what is the deadline? Compare this to the much more direct assessment of cost of delay.
Organizations wishing to adopt a CoD basis for prioritizing work are likely to need to develop greater understanding of and sensitivity to the value proposition of their services. Or, at the very worst, someone near the beginning of the value chain needs to have that understanding.
What does this have to do with Kanban?
Using CoD as the basis for deciding what to work on next is an excellent complement to working in a pull-based, just-in-time system for organizing work, which is precisely what Kanban is. It contrasts sharply with the push-based systems having no work in progress limits that characterize much of service management work today.
Knowledge workers accustomed to a push-based working system, especially in a command and control type environment, live in mortal fear of being asked where they are on a task and having to say, “I don’t know” or “I haven’t started it yet”. The consequence of this fear is to start working on as much as possible. This creates a situation of a large amount of context switching among tasks, which slows done the whole by a very significant factor.
Kanban tells us to delay the commitment to doing work until the last responsible moment. It is based on the assumption that each team and each worker has a work capacity that we should not try to exceed. Therefore, we only commit to doing work once we have a free slot available to do it. But, once we have committed to doing a work item, we focus our energies on completing it as rapidly as possible, ensuring the continuous and smooth flow of work.
The result of improving the flow of work is much faster completion of that work, much higher throughput of work and much less variation in the lead time required to do similar work. As teams progressively demonstrate their ability to deliver more quickly and more reliably, they gain the confidence and trust of their customers and they even make their bosses look good because. As trust increases, the perceived need for service level agreements decreases. But this is a story for another occasion.
 The diagrams in this posting are licensed to you under the terms of the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
The diagrams in this posting are licensed to you under the terms of the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
Hi there,
I have desperately tried for hours to figure out how the urgency profile imposed by an external deadline can be factored into CD3 calculation, but I just can’t get my head around it. Two questions bother me in particular:
1) Let’s say I must finish my project before a certain date or I’ll have to pay a one-time penalty of 100$. How do I model this? The CoD ist 0 before the deadline, it’s 100$ right on the deadline, but it’s 0 again right after the deadline (after I have paid the penalty, there’s no more sense in doing the project). When I want to calculate a CD3, I understand I have to normalize the CoD to a CoD per period. Is there a way to do this without defining an arbitrary time horizon (i.e. spreading the 100$ out over abitrarily chosen 12 months, even if i pay the fine just once)?
2) I want to give my stakeholders the CD3 value as a simple prioritization criterion (“sort this in descending order, and we’ll be alright”), and ideally, this value is stable. But how do I cope then with the change in the CoD, and, accordingly, the CD3, when it changes due to an external deadline? Do I have to present my stakeholders with a series of CD3s (“This month the CD3 of project A is 4.5 and the CD3 of project B is 2.4, so if we decide now, we should prefer project A. But beware, if we decide next month, due to the external deadline the CD3 of project B will rise to 4.8, so if we decide later, we should prefer project B”)? I’d prefer not to, because it makes the whole approach much less elegant and convincing from a top-level executive point of view (“So what do you want to tell me? Should I start A now, or should I do nothing now and start B in a month??”). Is there a way to arithmetically “fold” the development of the CD3 over time into a single value for an on-the-spot sorting of priorities that still yields when I look at it next month?
I’d be much obliged if you could untie this knot in my brain!
In response to your thoughtful remarks, I would suggest stepping back a little. I am not likely to be able to solve all your issues in one short response, but let me identify a few points that might help you.
Regarding the modeling of a penalty, I think that an out of pocket cost is but one cost that should be taken into account with a fixed date work item. The real issue is the loss of value to the customer due to your failure to deliver on time. Take an example. Suppose you need to deliver something to a customer for a trade show at which the customer typically gains some contracts, worth €xxx. The cost to the customer is the loss of revenue, not to mention the bad publicity. Compared to that, the penalty that the supplier might have to pay is probably very small. So, I am not so sure that the CoD goes back to 0 immediately after the deadline.
Regarding the issue of changing CoD, I think the starting point is to assume that once you have committed to doing the work, you go ahead and finish it, even if in the interim something else with a greater CoD comes along. Switching contexts in mid-stream is just going to slow everything down. I wouldn’t want to revalue the CoD every month (for example) and start and stop work on that basis.
Regarding the start times for work items, I would say that as soon as you have to capacity to take on an item, you do so. I don’t see “doing nothing” as a typical choice (although I can imagine rare circumstances when it might make sense).
Regarding the “top-level executive point of view”, this will always be a problem if those executives lack confidence in their team’s capability to deliver work in time to meet business needs and if they believe it is their role to interfere with the details of what work a team does. If this is the case, you need to work on developing that confidence and trust, which simply cannot be done as the result of a single implementation project. It is developed incrementally over the long haul. It is hard to gain, but easy to lose.