In a previous article, I provided an overview of artificial intelligence and machine learning from the perspective of delivering and managing services. In this article, I will review the service manager’s role in managing AI. So often, articles discuss roles such as the data scientist, the statistician or the programmer, relative to the design of an AI. But, as artificial intelligence is used to deliver and to manage services, we should also pay careful attention to the role of the service manager relative to the design and the use of artificial intelligence.
A table at the end of this article summarizes the service manager’s responsibilities.
This discussion will draw heavily on the current methods of implementing an artificial intelligence, especially the deep learning of a multi-layered artificial neural network. Other paradigms are regularly being investigated as methods for simulating intelligence and are likely to replace deep learning neural networks in the future. However, until such time as artificial general intelligence becomes available, most of the issues described below are independent of the specific technology used to emulate intelligence.
I will first clarify what I mean by a service manager, especially in contrast with AI specialists. I will follow this by examining the service manager’s role throughout my model of artificial intelligence in a service system (see Fig. 1). The reader may wish to review that article in parallel with this one.
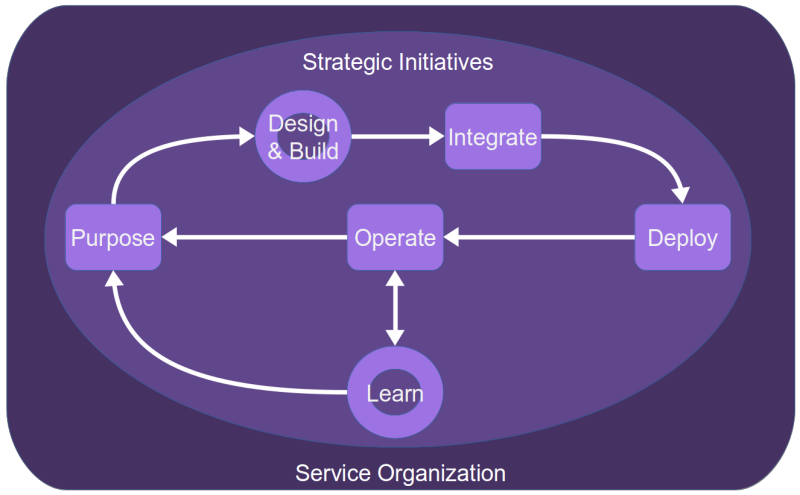
What is a Service Manager?
“Service Manager” is a somewhat vague term that might cover many different types of activities, competencies and responsibilities. Therefore, I will briefly describe what I mean by the term. Essentially, it covers two types of roles:
- a person accountable for the specifications of a service’s functionality and performance
- a person responsible for any specific activity in the delivery or management of a service
To a certain extent, that includes almost everyone in the service economy. However, I distinguish between those people with technical competencies specific to the design of an artificial intelligence and those who contribute to the work of those specialists by providing requirements, validating concepts and solutions and operating the resulting solutions.
Thus, I would distinguish between the service manager on the one hand and roles such as “data scientist” (what a horrible title!), statistician, or programmer, on the other hand. While these roles are not necessarily mutually exclusive, product owners or help desk agents or DBAs rarely have the know-how to take responsibility for modeling data for machine learning or choosing efficient techniques for reducing complex and voluminous data to manageable proportions.
Much of the work of designing artificial intelligences requires expressing complex systems in mathematical terms. Many non-specialists lack the intuition to understand what those mathematical formulæ imply in the real world. As a result, the functioning of an AI might appear to them as pure magic.
By describing the role of the service manager I hope to contribute to making AI less magical. I hope to help broaden an understanding among service managers of its limits and constraints. At the end of the day, AI is just another tool in our toolkits, helping us to achieve more effectively and efficiently the goals of the services we provide.
An alert service manager will thus avoid buying a pig in a poke when they acquire tools that promise “artificial intelligence”. An aware service manager will be better placed to understand the value of an AI and to decide when it can be useful; when it should be shelved.
Determining Strategies for the Use of AI
What are the policies that an organization might implement to govern the use of artificial intelligence? How should those policies be determined and maintained? Who should participate in this work? Ideally, all roles in a service provider organization should collaborate in determining such policies. Alas, all too often organizations cede that responsibility to the AI specialists. Service managers should actively participate in defining the strategic use of artificial intelligence.
Given the great success of many AIs in solving problems better and faster than humans could do alone, the value of an AI for certain types of tasks is well established. But, as for any other investment, an AI’s usefulness needs to be decided on a case by case basis. In other words, using AI is not automatically superior to a non-AI solution. Its use, costs, risks and potential benefits can be misunderstood, just as for any other tool.
Think of the policies that an organization already defines for such technical tools as programming languages, database managers or computing platforms. It is useful to set up policies regarding the preferred tools to use in each of those domains, to simplify supplier management, avoid redundant work, ensure integration capabilities and reduce the breadth of skills that an organization must maintain. This should also be the case for AI technology. Policies for AI use should be defined within the overall context of architectural decisions. Service managers should play their normal roles regarding those architectural decisions, depending on the broader context and culture of the organization.
Here are some examples of the specific use of AI that might be subject to policies:
- Choice of back end processing services
- Use of technical languages
- Choice of big data management tools
Regarding back end processing services, there might be many different applications for pattern recognition services, such as image content detection or natural language processing. Unless a solution using AI is sold as a black box, turnkey product, an organization may wish to prefer using a single back end service provider for such pattern recognition services.
Regarding technical languages, the programming languages used for AI generally make use of standardized libraries of functions, which libraries might be complemented or customized for the needs of the organization. Today, a very commonly used language for AI applications is Python. To reduce the number of different languages and libraries that need to be known, an organization may wish to identify a preferred language for any custom AI development.
Regarding big data, training artificial intelligences and maintaining their continual learning sometimes depends on processing very large amounts of data. Any policies preferring the use of a specific tool—such as Spark, Pachyderm or Hadoop—to process those large volumes of data may thus have an impact on the management of AIs.
It is my intention to highlight here the key aspects of what a service manager should keep in mind when providing input to the definitions of policies governing artificial intelligence. The rest of this article articulates those aspects.
Defining the Purpose of an AI
An AI, like any tool, is useless, perhaps even dangerous, when it is used without a clear understanding of its purpose. The service manager defines the purpose of any AI proposed as part of a solution to a problem in delivering or managing services.
The service manager owns the problem to be solved. Either the service manager experiences the problem directly in her or his work, or stands in for the voice of the customer. This might seem like a narrow view of the use of AI, but remember that today’s artificial intelligences are far from having general intelligence capabilities. Each AI is designed and built to handle a single type of capability.
For example, a service manager might be responsible for the reliable operation of a service delivered using information technology. From time to time, that service might have peaks of poor performance whose timing might be very difficult to predict in advance. Thus, the service manager has difficulty in taking steps in advance to avoid that poor performance. An AI might help identify the patterns of system behavior that often result in those peaks.
Or, perhaps customers use a service that helps them classify real-world objects or situations, such as facial recognition at a building’s entrance or early identification of malignant tumors. The service manager acting as the product owner of such services will specify the specific requirements that she or he believes will be useful to the service consumers.
Historically, the users of IT tools have often abdicated the responsibility for defining and understanding the problems they wish to solve. One often hears arguments of the sort, “The people who created the tools are supposed to be experts in this field, benefiting from input coming from many customers. We will benefit from whatever functionality that tool can offer us.” I have described in detail why this approach often results in huge levels of waste in my book, IT Tools for the Business when the Business is IT.
Inexperienced service managers might not understand what sort of problems an intelligent tool is apt to solve. The more the service manager understands the aptitudes of intelligent tools, the more likely is a good fit between the problem and an AI tool to be found. However, insofar as many intelligent tools require training for specific purposes and cannot be used as is and off the shelf, it may be necessary for the service manager to collaborate with an AI specialist to determine whether a given problem is apt to be solvable by an AI. The AI specialist has the knowledge of AI capabilities to perform this due diligence, knowledge that the service manager generally lacks.
Collecting the Data
Designing and building an AI starts with collecting the relevant data. Those data are the input for modeling the AI, training the AI, for testing and validating the AI and for solving the specific problems within the scope of the AI’s purpose. The service manager identifies the sources of data and provides information to the AI specialist about the likely biases and quality issues in the data.
Biased Service Manager? - Biased Data!
The biases, regarding what types of data are significant for the purposes of the AI, are a principal difficulty for the service manager in performing this task. For example, a service manager might believe that certain data could not possibly have anything to do with solving the problem. While this might be the case, consider the following. It is often useful to employ an AI for the very reason that certain relationships or patterns of data are simply not evident to the humans perusing them. The purpose of an AI is not to reproduce the biases of humans, but to go beyond them and find useful ways of treating input to achieve the desired output.
Not only are certain relationships not always obvious to the service manager, sometimes anti-intuitive techniques improve understanding. A good example of this would be the use of stochastic resonance to enhance the detection of weak signals in date. Whereas most people attempt to reduce the level of noise in data, stochastic resonance uses the addition of noise as a way of detecting patterns more easily.
Indeed, we have seen clear evidence that so-called deep learning allows AIs to go far beyond those AIs that attempt to reduce human knowledge to a set of rules. The best examples of this are the game playing AIs. Trying to reduce games like chess or go to a set of rules results in an impossibly cumbersome, algorithmic application that is simply not a very good game player. Deep learning, on the other hand, allows AIs to quickly surpass their human counterparts.
Typical computer-based service systems record a huge quantity of time series data documenting how the components of the system behave. For example, service acts are typically sets of one or more transactions whose parameters are (or should be) logged. At the same time, the service manager should ensure the logging of the state changes and capacity use of the contributing system components, such as computer processors, network interfaces, database managers, load balancers, etc.
Service management systems, too, gather much time series data. Much of those data are unstructured or are provided with a structure that reflects strong human biases. For example, a tool might be used to log problems and the incidents that are presumably caused by those problems. Misidentifying which incidents are caused by which problems reflects the biases of the problem managers. But even worse are the biases that lead to hierarchic taxonomies of causality, taxonomies that assume incorrectly that there is a one to one relationship between an incident and a cause. Perhaps the best way of understanding problems is to think of them as bundles of causes with some temporal or logical relationships.1
Supervised and Unsupervised Learning
So how should the service manager proceed in identifying data to collect for the AI? This depends on the degree to which the AI will use supervised learning or unsupervised learning. In the former case, someone needs to label each instance of data with a corresponding name. These is easiest to understand with such applications as image identification. To train the AI with a given set of training data, someone must tell it that a certain collection of pixels contain an image of a cat, a dog, a letter, or whatever you are trying to identify. In other words, a human must inform the AI of the right answers for certain data so that the AI will be able to identify on its own other images. The entire set of data to collect in this case would be the images themselves and the categories depicted in each image.
In the case of unsupervised learning, the AI determines on its own certain patterns in the data. It cannot know, however, whether those patterns are relevant to the particular problem the service manager wishes to solve. As a result, an iterative approach to identifying the data to collect may be helpful. Start with a broad collection of data. If the AI turns out to be unable to correlate certain data with useful output, the service manager may wish to remove that data from the inputs to the AI.
Of course, the more data collected, the more expensive, complicated and time-consuming the functioning of the AI. The AI specialist applies data regression techniques during the modeling of the data. This regression simplifies the modeling of the data used. Awareness of such decisions may influence the service manager’s data collection activities.
The Exploration–Exploitation Dilemma
Collecting data and modeling an AI solution are subject to the exploration–exploitation dilemma. This dilemma asks whether it is better to invest resources to learn more or better to deliver results and gain their benefits now. The former focuses on longer term optimization, but without any guarantee that additional exploration will yield a better solution. The latter focuses on shorter term benefits, leaving the solution open to possibly significant improvement.
Various strategies may be applied to resolve the balance between additional exploration and immediate exploitation. These strategies are generally based on statistical analysis, Bayesian theory, game theory and so forth. The choice and the application of these techniques are in the realm of the AI specialists expertise.
However, all of these strategies are constrained by business needs that are in the realm of the service manager’s expertise. In particular, the service manager should consider:
- the cost of delay
- the available cashflow
- the sensitivity to risk
A cost of delay analysis assesses the opportunity costs of delaying a solution, as well as the impact of potentially missing fixed deadlines. A cashflow analysis determines how much cash is available for continued work and when it will be available. The service manager should also consider various risks, such as:
- the risk of competitors providing a better or earlier solution
- the minimum acceptable probability of any solution provided by the AI (see the discussion of PAC, below)
Resolving the exploration–exploitation dilemma helps answer such questions as:
- Is enough data collected?
- Does the collected data allow for adequate modeling of the solution?
Modeling the AI Solution
The AI component of the solution to the problem to be solved generally requires mathematical, statistical and machine learning knowledge that is not often held by service managers. The service manager is thus a source of functional information about the problem, but specialists will realize the model of the solution. Perhaps this situation will change as AI creation tools become more sophisticated.
As a subject matter expert in the domain of the problem to be solved, the service manager provides guidance concerning:
- the potential ranges of the data inputs
- the applicability of the proposed solution
- whether unusual data points are random outliers or significant values that must be handled by the solution
- the meaning of clusters of data
Developing the solution’s model is generally an iterative process requiring regular exchanges of information between the service manager and the specialist. Although AIs are based on scientific methods, there is much art in finding what is important and what can be safely ignored in modeling the data, thus the need for multiple iterations.
AI specialists have applied various methods, defined from a data mining perspective, to the development of models used in AI solutions. Some of these methods, like SEMMA, remain highly technical in nature and leave little room for the direct participation by the service manager. Others, such as CRISP-DM, define a phase of “Business Understanding”. This phase maps directly to the Definition of Purpose in our model. Its second and third phases concern data and map to Collecting the Data in the model used in the current discussion.
Training the AI
After identifying an appropriate model, the AI is generally trained using a test data set. The technical purpose of the training is to minimize the cost function of the model by finding that function’s optimal parameters. The cost function measures the gap between the observed values when using the training data and the predicted values according to the AI model.
Train to Optimize Cost
Imagine that you are in a mountainous area, with many peaks and valleys. Optimizing the cost function would be like trying to find the lowest altitude valley within the region. Intuition tells you that following the course of water will inevitably lead you to the lowest area. Similarly, there are various mathematical methods for approximating the lowest cost, such as the technique of gradient descent.
Although an understanding of differential calculus is useful in understanding the theory behind training, the service manager is not expected to understand and to apply those optimization methods. On the other hand, the service manager should be aware of the limits to the optimization methods in use. To use the analogy mentioned above, if you are in the mountains, it is easy enough to find the lowest point within a given valley. But it can be very hard to know if the next valley over is even lower. Similarly, mathematical optimization often cannot guarantee that it finds the optimal model and recognizes all local minima. There are several reasons for this:
- the data in the training set might reflect significant biases
- the cost of finding the optimal values might exceed the available resources
- there is a risk of over-training an AI, such that the cost for the training data set might be very low, but the predictive value for the test data and the production data might also be low
- a simpler, cheaper model might provide good enough solutions for the problem at hand
It is the service manager who should answer the questions about what resources are available for learning and whether the solution is good enough. Questions about required time to market, design budget and operating budget, availability of computing power and performance levels should be answered by the AI solution’s owner, not by the solution’s designer. The issue of the exploration-exploitation dilemma (see above) is also applicable here.
Transfer Learning and Reinforcement Learning
At least two different approaches are used for training and learning. They have distinct responsibilities for the service manager.
Transfer Learning
Transfer learning looks at training as the sum of lessons learned, starting from the most basic and going to the most complicated. This is generally how we teach students in schools. For example, you must first learn some algebra before learning Euclidean geometry or before learning about functions and limits. You must learn about limits before learning about integral calculus, and so forth.
In machine learning, consider the example of natural language processing. An AI can be taught to understand various basic aspects of a natural language, such as English. That basic understanding can be transferred rather easily from one application to another. However, in most NLP applications it is also necessary to provide domain-specific training on the use of the language. That domain-specific use of language is the jargon of that domain. Not only does that jargon vary from domain to domain and from organization to organization, it tends to change very rapidly.
In service management, that domain-specific knowledge needs to be provided by the service manager about the specific services being offered in the context of the specific service provider, the consumers and the market and regulatory context. But if the services are delivered or managed using information technology, transfer learning can provide much of the training about that technology with a head start.
Reinforcement Learning
Reinforcement learning is more of a recursive approach to training. Each training case results in some feedback that may be understood as a reward for having learned a lesson. The greater the reward, the more the particular connections in the neural network are strengthened.
Think in terms of the strategies and values of an organization. Each calculation by an AI can be assessed according to whether the output is closer to following those strategies or implementing those values. A simple example might be expressed in terms of service availability, customer satisfaction and cost. An AI proposes a resolution of an incident. The resulting cost, impact on service availability and customer satisfaction are assessed and fed back into the weighting mechanism of the AI. The service manager must provide information about what should be fed back and how it should be weighted.
How much Training is Enough?
The Internet is replete with stories about training AIs with huge volumes of data. But how much training is enough? The more we train, the longer it takes for a service to get to market, the more it costs, the lower will be the return on the investment in that training.
The answer to this question depends on various factors:
- How general is the intelligence of the AI supposed to be?
- The learning rate of the AI
- The exploration–exploitation dilemma, as described above
Using Bayes' Theorem
The service manager should have at least a basic acquaintance with Bayes’ Theorem to understand the issues. Bayes’ Theorem describes the impact of incremental increases in knowledge about a system on the probabilities in that system.
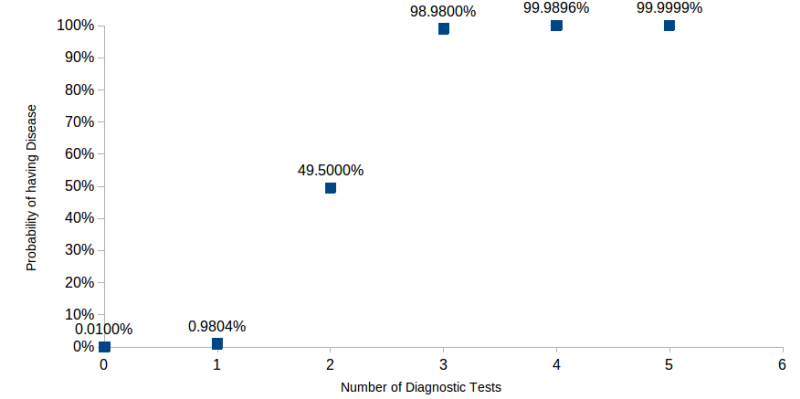
A common example of this, and why our intuitions are often wrong, is in understanding the diagnosis of a disease. Suppose a disease is randomly distributed in a population and is found in 1 out of every 10’000 persons. And suppose there is a diagnostic test for that disease that is accurate 99% of the time. You take the test and it returns a positive result. What is the probability that you have the disease?
If you are like many people, you will think that it is 99% probable that you have the disease. But the correct answer is that there is slightly less than a 1% probability that you have the disease. The intuition is that so few people have the disease that the percentage of false positives is very large compared to the number of ill people.
Now, suppose you get a second opinion on your having the disease. This same diagnostic test also returns a positive. With this new information, what is the probability that you truly have the disease? It jumps to almost 50%.
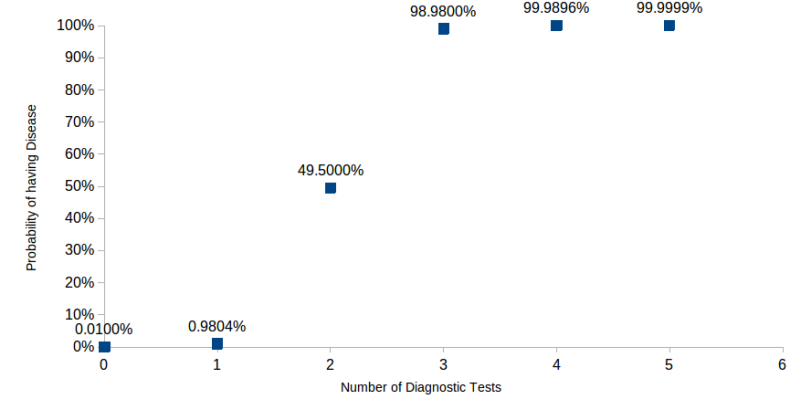
We see in Fig. 2 that the probability of having the disease without any diagnostic tests is .01% (1 person out of 10’000). Because this frequency is very low, a positive result from a single diagnostic test brings the probability up to only .98%, even though the test yields few false positives. Note, however, that from 3 tests and on, the probability of having the disease is about 99% or higher. After the third test, additional tests add very little information.
The intuition behind this example should already be understood by computer system managers. Suppose an alert is received indicating that a processor load has exceeded 70%. We do not immediately go out and buy more processing power because we know that such events are rare and that occasional spikes in load are to be expected. But what happens if we get three such alerts within 3 minutes? The correlation of these alerts in time tell us that each new alert indicates that the previous alerts were increasingly indicators of a need for more capacity. We start to pay close attention to the patterns of load of the processor and are apt to rebalance loads or add capacity before, one hopes, the customers start to complain of slow performance.
Now, let’s apply the same thinking to training an AI. Remember that each training case helps increase the probability that the AI will yield the correct output (insofar as the training data is pertinent). Indeed, a medical diagnosis AI would be using the results of a diagnostic test as one input, among others. Since the scope of our problem is very narrow (examples: does the person have the disease or not; is the probability of a service being completely down greater than 90%; etc.), we can start to get very useful results with relatively few training cases.
There are two reasons why the number of training cases might have to be much larger:
- When the accuracy of an indicator is not known in advance
- When the scope of the problem to be resolved is broad
In the case of the medical diagnostic test described above, we claimed in advance that it delivers only 1% false positives or false negatives (i.e., it is 99% accurate). But what if we did not know how accurate the test is? In that case, we would need to examine many training cases to estimate its accuracy. That accuracy would be expressed in a neural network as a weight of a node, the node corresponding to the result of the test.
Consequently, the service manager may provide input regarding what inputs to the AI have previously known values and which input weights need to be discovered through the training.
A good example of how this works is the natural language processing used in chatbots and other customer service applications. A back-end NLP processor is likely to be trained already to understand the basic grammar, syntax and semantics of the language(s) in use. You would not have to train it to understand that “we” is the plural of “I” or that “use”, “using”, “uses” and “used” may be forms of the same verb.
But, if you expect to get good results from the AI, you shall have to train it to recognize the special aspects and idiosyncrasies of your own organization and its jargon—the abbreviations it uses; the names of the services you use; the terms with unusual meanings; the proper nouns, like department or job names; and so forth.
A single NLP processor dedicated to diagnosing problems in a single service might require only a few dozen training examples to become useful. On the other hand, a general NLP processor that is supposed to understand any sort of customer service request might require thousands of training examples to achieve that goal.
Learning rates
The amount of training required also depends on the learning rate of the AI. Without getting into technical details, the learning rate is a factor that determines how much an AI corrects its weighting for a new case. While one might think that a high learning rate would be good, in practical terms, the learning rate should be neither too high nor too low. When the learning rate is too high, it over-compensates for the influence of a new case. When the learning rate is too low, it takes an inordinately large number of cases to train the AI.
Let’s take as an example an AI whose purpose is to predict whether a service will be up or down based on various factors, including whether or not a client can log in to the service. When the learning rate is high, it will take only a few cases for the AI to decide that not being able to log in is a strong indicator of the service being down. However, there might be other reasons that a client cannot log in. If the learning rate is too high, then adding a new case where the service is up but a client could not log in (for other reasons) might lead the AI to overreact and consider that failure to log in is a poor indicator of the service being down. So, we lower the learning rate to avoid an untoward thrashing. While the service manager probably does not need to understand the technical details of adjusting the learning rate, it should be understood that this parameter does need tuning and that multiple iterations might be necessary before finding a reasonable rate.
Integrating the AI
The service designer must normally integrate an artificial intelligences into a more complex solution to make it usable by some service consumer. For example, AI might be useful to identify an image as describing a certain person. But if it is to be used as a means for allowing or denying access by people to a building, it must be integrated with database management, cameras, physical gateways and locks and potentially other management systems, such as time presence systems.
A service manager may well be the owner of the overall system, whether it be a system used to deliver services or to manage services. As an owner, the service manager has the same responsibilities as for any other solution, whether it includes AI components or not. The integration of an AI component does not pose any special requirements for these comprehensive systems.
That being said, the current market has wide offerings for AI-type services that are easily integrated into broader solutions. This is especially the case for such applications as natural language processing and image identification. These services offer the possibility of a platform that obliges you to provide the training data and to train the AI; or a platform that has already been trained; or some hybrid of the two. Furthermore, some providers offer services where your data is segregated from all other data and is confidential, whereas other services handle all customers’ requests with a common database, even if the specific requests remain confidential.
An example of the latter would be Pl@ntNet. This supervised learning service allows you to submit photographs of plants and it provides identifications of the probable species in the image, together with validated images of those species. It further allows subscribers to validate a user’s identification. In such cases, the submitted image is further validated by experts and the image becomes part of the training data for the database. Thus, all users may benefit from each other’s photographs. Thus, Pl@ntNet is a solution for identifying plants consisting of a database of identified images, a description of plant metadata, an image processing service and either smartphone or browser front ends.
Operating an AI
Operating an AI, both from the service delivery perspective and from the service management perspective, is very similar to any other service delivered using IT components. However, the operators of an AI should take into account the fact that they operate probabilistically, not deterministically.
Probabilistic operation and the concept of being probably approximately correct (PAC) leads to three questions for the service manager to answer:
- How approximate is good enough?
- How high a probability is good enough?
- How should you handle results where the probability is in a grey zone—not so low as to be rejected out of hand, but not quite high enough to be comfortable?
How Approximate is Good Enough?
This question is the first part of the assessment of the quality of an output. The answer depends on the use to which the output will be put and the risks associated with a given error. If I manufacture screws, an approximate tolerance for the diameter of the screw that is ±.1% might be perfectly adequate for the carpentry work done around a home. But for an application in aeronautics, such an approximate tolerance might pose unacceptable risks to the safety of an airplane and its passengers. Perhaps a tolerance of ±.001% might be required in that case.
How Probable is Good Enough?
This is the second part of the assessment of the quality of an output. There is, of course, no single answer to this question. The assessment depends largely on the risk associated with giving a wrong answer. The risk associated with a false negative in a cancer-detecting service is quite different from the risk of a false negative in a SPAM-detecting service.
The purpose of the AI also comes into question. One service manager might wish to use an AI because it delivers a much higher quality result than can a human. Top quality AIs do a better job of cancer detection than physicians and play many games better than their human counterparts.
But AIs are also used because they are faster, cheaper and more available than humans, even if the quality of their results is not better than that of humans. An AI that can filter 99.9% of the 100’000 SPAM messages arriving each day at a large company is immensely more efficient (and probably more effective) than having each email recipient filtering his or her own messages. A chatbot with natural language processing can operate around the clock and answer perhaps 80% of all inquiries at a tiny fraction of the cost of human customer service agents. If you search on the Internet for a picture of a tiger, your choice will be much larger if an AI is used to recognize the tigers than if we depend on a human having labeled the pictures manually.
That being said, there are some rules of thumb regarding acceptable probabilities of AI output. The threshold between unacceptable and good enough is probably somewhere between 75% and 85%, again, depending on the risks involved. This is a long introduction to the statement that the service manager using or owning the AI shall have to specify that threshold.
How to Handle Borderline Cases?
Once a threshold has been specified, the AI itself can recognize if its own result is below or near that threshold. How you handle those cases is part of the design of the overall system in which the AI is embedded.
A common example would be a chatbot using natural language processing. The AI attempts to understand the intent of each input by the chatbot user. Suppose you fix the acceptable threshold at 80% and the probability of a certain identified intent is set at 50%. Typically, the chatbot will jump to a special low probability response, of the sort, “Hey, I didn’t quite get what you mean. Please rephrase.”
A more sophisticated chatbot might distinguish between the cases where it is quite sure that it does not understand the intent and the cases where it thinks it understands or there are a few possible understandings of the intent. In the latter case, the chatbot could do what any human would do in the same situation. It could respond with, “I think you mean xxx, but maybe you were talking about yyy.” The user understands that clarification is in order.
Thus far, I have described the cases where the AI tries to handle its own failures and ambiguities on its own. An alternate solution would be to escalate the issue to a human service manager. This could be done in an automatic way, for example, by switching the chatbot conversation to a person, or in a manual way. In high risk situations, the service owner might prefer that only a human takes decisions and acts based on the AI’s analysis. Thus, an AI might provide the probability that a tumor is malignant, but only a physician will prescribe a course of treatment.
Here is an example for a common service management procedure. An IT user cannot log in to an application and needs to have a password reset. The user calls a telephone number and selects the password reset option. An AI does voice identification to ensure the identity of the caller. Suppose a threshold has been fixed at 95% for the probability of the identification. If the identification is positive, a message is sent to the caller with instructions for the reset. If the identification is negative, the request is transmitted to a human agent for further processing. If the identification is borderline, the system might try to keep the caller talking to get a better sample and a less ambiguous identification.
The world is a very ambiguous place where most of our activities cannot be reduced to algorithmic calculations. Artificial intelligence’s probabilistic approach to data processing is a good match for that inherent ambiguity. But when we use such tools we must remember that the results provided are only probably useful.
Continual Improvement of AIs
Improving an AI while it is in an operational phase may have three aspects:
- Using learning from operational use
- Remodeling
- Cleaning existing neuron weightings
Learning from operational use
Learning during the operational phase of an AI is an inherent part of its continual improvement. Once an AI is trained and integrated into a solution, it may provide useful output. However, given that the output of an AI should be understood as a probable answer, rather than the correct answer, it is susceptible to continual improvement. As we saw above, an AI will deliver a certain number of false negatives and false positives, depending on the thresholds defined. As with any defects in a system, these erroneous cases are also opportunities for improvement. Much of the improvement of an AI used for service management or service delivery is under the responsibility of the service manager.
The output using an AI service may be fed back to the AI as part of a learning procedure, thereby improving the AI. For example, the hairy stems and leaves of Ranunculus lanuginosus (Woolly Buttercup) are distinguishing characteristics (see Fig. 3). However, this feature might not be easily detectable in the photographs submitted to Pl@ntNet. As a result, the image-identifying AI might not understand the difference between lanuginosus and Ranunculus auricomus (Goldilocks Buttercup) (see Fig. 4). As more photographs are submitted and validated, the AI may improve its ability to distinguish the various species of buttercups. In short, more data allows for continual training and improvement in the probabilities associated with the identifications.


In other cases, the population of input data to the AI evolves, such that the initial training data set becomes a less and less representative sample of that population. In an unsupervised learning system, the AI might detect new clusters of data or patterns that did not exist before. As with the initial training, the subject matter expert must intervene to provide meaning to those new patterns. Similarly, in a supervised learning approach, the expert must make a positive identification of the new cases so that the AI can learn to distinguish them. In both cases, the service manager may be playing the role of the subject matter expert.
In more severe cases of population evolution, the model itself might become less and less useful. For example, in the early phase of the lifetime of a service, a linear model of the data might be perfectly adequate. However, as the population of service consumers becomes more diverse or as consumers use the service more and more, that model might be better represented as a polynomial or other function. As a population of consumers becomes more segmented, it might be necessary to evolve from a sigmoid function (Fig. 2), used to distinguish two categories, to a more complex function identifying multiple categories of consumers (Fig. 3).
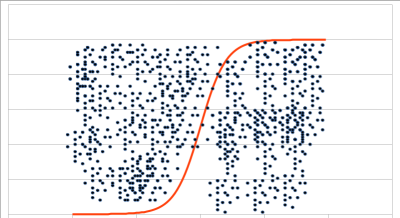
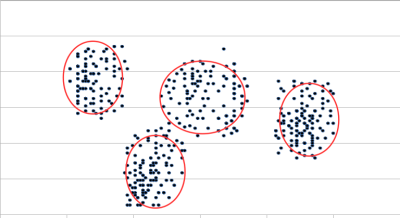
I discussed above the question of how much training is enough and whether the weighting of an input should be discovered by the AI or assigned a value previously known. There is perhaps a strong temptation to pre-assign weightings for inputs, based on the service manager’s experience and intuition. While this has the advantage of simplifying the training process, it also reproduces in the AI the service manager’s biases, which we should try to avoid.
Part of the solution to this issue is addressed by calibrating the assumptions made by the service manager. Douglas Hubbard discusses at length the question of calibration. I strongly advise all service managers to read his books or follow his training.
Remodeling an AI
The AI specialist may scrap the existing model and replace it with a new model. In this case, the cycle of development and reuse starts again. The service manager plays the same roles as before.
Cleaning an AI
In the course of training and operational use, an AI will accumulate data that leads to bad probabilities and wrong results. If the training has converged on the desired results, operational learning will increasingly submerge these false positives under the weight of the true positives. But this is a little like painting over dirty walls rather than cleaning them, or buying a stronger fan for your computer, rather than cleaning the air filter.
There are technical reasons for detecting the neurons in an artificial neural network and cleaning them. In particular, the number of neurons in the network determines its overall capacity. As these neurons increasingly hold garbage information, the overall capacity of the network decreases.
The ability to detect such neurons is only now being developed and is highly technical in nature. However, the service manager will play a role in helping to identify the criteria under which such neurons may be detected.
Neural networks are sometimes criticized because it is not quite clear how a network arrives at a certain conclusion. Since one of the main purposes of this article is to help service managers get away from treating AIs as black boxes, let’s examine how an understanding of how an AI makes decisions helps the service manager to improve the AI.
A number of tools have been developed to shed light on how neural networks make decisions. These tools can be thought of as answering the question, “What specifically was it about the input that led the AI to decide on the output?” These tools are easiest to understand in terms of image processing.
Suppose an AI is used to provide physical access control to a building via facial recognition. One person is regularly denied access in spite of being a bona fide employee who been photographed as part of the normal training of the AI system. Obviously, the AI is missing some key features that would enable it to recognize that person more reliably. Other examples would be AIs that regularly mistake baboons for automobiles or husbands for lawn mowers.
If we are to improve reliability, we need to have some information about the source of the confusion and how to correct it. Simply re-scanning the person’s face is not going to solve the problem.2 AI specialists use methods such as RISE and CEM to better understand how a neural network makes decisions and even proposing what additional information would be required to improve the network’s training. Service manager’s may be called on to provide that information.
Summary of Service Manager Responsibilities
| Activity | Responsibilities |
|---|---|
| Define AI strategy |
|
| Define AI purpose |
|
| Identify data to collect |
|
| Modeling solution |
|
| Training |
|
| Integrating |
|
| Operating |
|
| Improving |
|
As we can see, far from being a passive actor or simple consumer of artificial intelligence, the service manager has many key roles to play throughout the life of an AI.
![]() The article by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Bibliography
[a] Hubbard, Douglas, How to Measure Anything. Finding the Value of “Intangibles” in Business, 2nd ed. John Wiley & Sons, Inc. ISBN 978-0-470-53939-2.
[b] Galef, Julia, “A visual guide to Bayesian thinking“.
[c] Fachechi, Alberto, Elena Agliari, Adriano Barra (2019). “Dreaming neural networks: Forgetting spurious memories and reinforcing pure ones”, Neural Networks 112, pp. 24-40, https://doi.org/10.1016/j.neunet.2019.01.006.
Notes
Credits
Unless otherwise indicated here, the diagrams are the work of the author.
Fig. 3: By Fornax – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=4002061
Fig. 4: By I, Hugo.arg, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2266929
Thank you Mr. Robert for such an interesting article. Question: what kind of work or projects are you leading at your country. For your answer, thks in advance!